[ 충돌 해결 ]
[ 충돌 ]
해시 함수가 서로 다른 입력값에 대해 동일한 해시 테이블 주소를 반환하는 것을 일컬어 "충돌"이라고 한다 .
어떠한 해시 함수든 , 모든 입력값에 대해 고유한 해시값을 만들지는 못한다 . 즉 ,충돌은 불가피하다 .
충돌의 해결방법은 크게 두가지이다 .
- 개방 해싱 (Open Hashing) : 해시 테이블의 주소 바깥에 새로운 공간을 할당 , 문제를 해결
- 폐쇄 해싱 (Closed Hashing) : 처음에 주어진 해시테이블의 공간 안에서 문제를 해결
[ 체이닝 ]
체이닝은 개방 해싱 기반의 충돌 해결 기법이다 .
해시 함수가 서로 다른 키에 대해 같은 주소값을 반환해서 충돌이 발생하면 ,
각 데이터를 해당 주소에 있는 링크드 리스트에 삽입 , 문제를 해결하는 기법이다 .
체이닝은 충돌이 일어나면 링크드 리스트에 사슬처럼 주렁 주렁 엮는다는 의미에서 붙은 이름이다 .

=>위와 같이 체이닝 기반의 해시 테이블은 데이터 대신 링크드 리스트에 대한 포인터를 관리한다 .
데이터는 링크드 리스트에 저장된다 .
=>체이닝을 사용한다고 해시 함수를 수정할 필요는 없다 . 해시 함수가 만들어낸 주소값을 데이터가 직접 사용하지 않고
링크드 리스트가 사용한다는 것 말고는 해시 함수의 역할이 똑같기 때문이다.
다만 , 데이터를 해시 테이블에 삽입 , 탐색하는 연산은 새 알고리즘에 맞춰 바뀔 필요가 있다 .
삽입 연산은 충돌이 발생할 것을 고려 , 탐색과 삭제 연산은 충돌이 이미 발생했을 것을 고려하여 설계해야 한다 .
[ 체이닝 기반 해시 테이블 : 들어가기 전에 ]
키와 데이터의 자료형 , 링크드 리스트의 선언을 먼저 알아야 한다 .
typedef char* KeyType; //키의 자료형
typedef char* ValueType; //키의 짝으로 입력될 데이터의 자료형
//링크드 리스트의 노드
typedef struct tagNode
{
KeyType Key;
ValueType Value;
//다음 노드의 주소
struct tagNode* Next;
}Node;
//링크드 리스트
typedef Node* List;
//해시 테이블
typedef struct tagHashTable
{
int TableSize;
List* Table;
}HashTanle;
[ 체이닝 기반 해시 테이블 : 탐색 ]
탐색 연산은 "충돌이 발생했음"을 고려해서 설계 해야 한다 .
체이닝 기반 해시 테이블에서는 다음과 같은 순서로 탐색을 수행한다.
- 찾고자 하는 목표값 해싱 ,링크드 리스트가 저장된 주소를 찾는다 .
- 이 주소를 이용 , 해시 테이블에 저장된 링크드 리스트에 대한 포인터를 생성한다 .
- 링크드 리스트의 앞에서 뒤까지 차례로 이동하며 , 목표값이 저장되어 있는지 비교하며 , 목표값과 링크드 리스트 내의 노드값이 일치하면 해당 노드의 주소를 반환한다 .
ValueType CHT_Get(HashTable * HT , KeyType Key)
{
//주소를 해싱한다 .
int Address = CHT_Hash(Key,strlen(Key),HT->TableSize);
//해싱한 주소에 있는 링크드 리스트를 가져온다
List TheList = HT->Table[Address];
List Target = NULL;
if(TheList==Null)
return NULL;
//원하는 값을 찾기 전까지 순차 탐색
while(1)
{
//맞는 값을 찾았다면
if(strcmp(TheList->Key,Key)==0)
{
Target = TheList;
break;
}
//다음 노드가 없다면 (끝까지 못 찾았다면)
if(The List->Next == NULL)
return NULL;
else
//찾는 노드가 아니라면 다음 노드로 리스트를 옮김
TheList = TheList->Next;
}
return Target->Value;
}
[ 체이닝 기반 해시 테이블 : 삽입 ]
해시 함수를 이용해서 데이터가 삽입될 링크드 리스트의 주소를 얻어 , 링크드 리스트가 비어있다면 데이터 바로 삽입 /
아니라면 링크드 리스트의 "헤드 앞"에 삽입한다
헤드 앞에 삽입하는 이유
=>새로운 데이터를 링크드 리스트의 테일로 만들고 싶다면 순차탐색을 수행, 테일 노드를 찾아야 한다 .
새 리스트가 헤드 앞에 삽입한다면 (가장 앞에) 쓸데 없는 순차 탐색으로 해시 테이블의 성능 저하를 막을 수 있다 .
void CHT_Set(HashTable* HT , KeyType Key , ValueType Value)
{
//주소값을 해싱
int Address = CHT_Hash(Key, strlen(Key),HT->TableSize);
//새 노드를 생성
Node*NewNode = CHT_CreateNode(Key,Value);
//해당 주소가 비어 있는 경우
if(HT->Table[Address]==NULL)
HT->Table[Address]=NewNode;
//해당 주소가 차 있다면
else
{
//헤드에 새 데이터를 삽입
List L = HT->Table[Address];
NewNode->Next = L;
HT->Table[Address] = NewNode;
printf("Collision Occured : Key(%s) , Address (%d)\n" ,key,Address);
}
}
[ 체이닝 성능의 개선]
원하는 데이터를 찾기 위해 순차탐색을 해야하는 링크드 리스트의 단점을 그대로 가져간다 .
이는 레드 블랙 트리와 같은 이진트리의 사용으로 해결 할 수 있다 .
(해시 함수의 성능이 좋지 않아 충돌이 잦다면 해시테이블 + 이진탐색트리는 좋은 선택일것이다)
[ 체이닝 구현 ]

[ Chaning.h ]
#ifndef CHANING_H
#define CHANING_H
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//키와 밸류
typedef char* KeyType;
typedef char* ValueType;
//노드
typedef struct tagNode
{
KeyType Key;
ValueType Value;
struct tagNode* Next;
}Node;
//노드 배열
typedef Node* List;
//해쉬 테이블
typedef struct tagHashTable
{
int TableSize;
List* Table;
}HashTable;
//해쉬 테이블의 생성
HashTable* CHT_CreateHashTable(int TableSize);
//해쉬 테이블의 삭제
void CHT_DestroyHashTable(HashTable* HT);
//링크드 리스트 삭제
void CHT_DestroyList(List L);
//노드의 삭제
void CHT_DestroyNode(Node* TheNode);
//노드의 생성
Node* CHT_CreateNode(KeyType Key, ValueType Value);
//Set
void CHT_Set(HashTable* HT, KeyType Key, ValueType Value);
//Get
ValueType CHT_Get(HashTable* HT, KeyType Key);
//Hash
int CHT_Hash(KeyType Key, int KeyLength, int TableSize);
#endif // !CHANING_H[ Chaning.cpp ]
#include"Chaning.h"
//해쉬 테이블의 생성
//해쉬 테이블은 1. Table (링크드 리스트 배열) => 2 . List (링크드 리스트) => 3. Node (링크드 리스트를 구성하는 노드)로 구성
HashTable* CHT_CreateHashTable(int TableSize)
{
//해쉬 테이블
HashTable* HT = (HashTable*)malloc(sizeof(HashTable));
HT->TableSize = TableSize;
//Table (링크드 리스트 배열)
HT->Table = (List*)malloc(sizeof(List) * TableSize);
//0으로 초기화
memset(HT->Table, 0, sizeof(List) * TableSize);
return HT;
}
//해쉬 테이블의 삭제
void CHT_DestroyHashTable(HashTable* HT)
{
int i = 0;
//각 링크드 리스트를 자유 저장소에서 해지
for (i = 0; i < HT->TableSize; i++)
{
List L = HT->Table[i];
CHT_DestroyList(L);
}
//해시 테이블을 자유 저장소에서 제거
free(HT->Table);
free(HT);
printf("\n삭제 완료");
}
//리스트의 삭제
void CHT_DestroyList(List L)
{
if (L == NULL)
return;
//다음 리스트를 삭제하고
if (L->Next != NULL)
CHT_DestroyList(L->Next);
//노드(나)를 삭제한다
CHT_DestroyNode(L);
}
//노드의 삭제
void CHT_DestroyNode(Node* TheNode)
{
free(TheNode->Key);
free(TheNode->Value);
free(TheNode);
}
//노드의 생성
Node* CHT_CreateNode(KeyType Key, ValueType Value)
{
Node* NewNode = (Node*)malloc(sizeof(Node));
//char*이므로 다음과 같이 초기화
NewNode->Key = (char*)malloc(sizeof(char) * (strlen(Key) + 1));
strcpy(NewNode->Key, Key);
NewNode->Value = (char*)malloc(sizeof(char) * (strlen(Value) + 1));
strcpy(NewNode->Value, Value);
NewNode->Next = NULL;
return NewNode;
}
//Set
void CHT_Set(HashTable* HT, KeyType Key, ValueType Value)
{
//주소값을 해싱
int Address = CHT_Hash(Key, strlen(Key), HT->TableSize);
//새로운 노드를 생성
Node*NewNode= CHT_CreateNode(Key, Value);
//해당 주소가 비어 있다면
if (HT->Table[Address] == NULL)
{
HT->Table[Address] = NewNode;
}
else
{
//////헤드에 새로운 노드를 넣는다 .
List Temp = HT->Table[Address];
NewNode->Next = Temp;
HT->Table[Address] = NewNode;
printf("Collision Occured : Key (%s) , Value (%d)\n\n", Key, Address);
}
}
//Get
ValueType CHT_Get(HashTable* HT, KeyType Key)
{
//주소를 해싱한다
int Address = CHT_Hash(Key, strlen(Key), HT->TableSize);
//해당 주소의 링크드 리스트를 가져온다
List L = HT->Table[Address];
List Target = NULL;
if (L == NULL)
return NULL;
//원하는 값을 찾기까지 순차 탐색
while(1)
{
if (strcmp(L->Key, Key) == 0)
{
Target = L;
break;
}
if (L->Next == NULL)
return NULL;
else
L = L->Next;
}
return Target->Value;
}
//Hash
int CHT_Hash(KeyType Key, int KeyLength, int TableSize)
{
int i = 0;
int HashValue = 0;
for (int i = 0; i < KeyLength;i++)
{
HashValue = (HashValue << 3) + Key[i];
}
HashValue = HashValue % TableSize;
return HashValue;
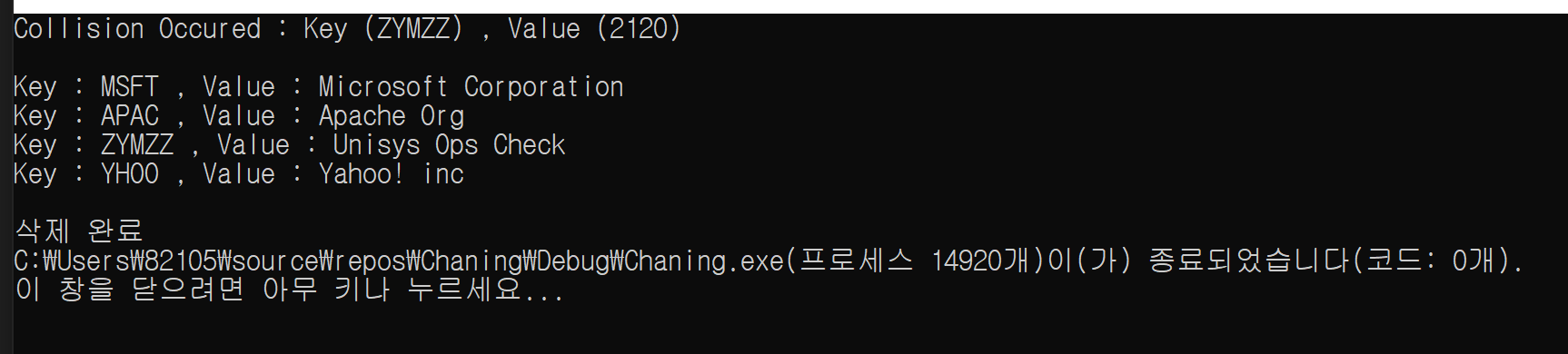
}[ Test.cpp ]
#include"Chaning.h"
int main(void)
{
HashTable* HT = CHT_CreateHashTable(12289);
CHT_Set(HT, (KeyType)"MSFT", (ValueType)"Microsoft Corporation");
CHT_Set(HT, (KeyType)"APAC", (ValueType)"Apache Org");
CHT_Set(HT, (KeyType)"ZYMZZ", (ValueType)"Unisys Ops Check");//APAC와 충돌발생
CHT_Set(HT, (KeyType)"YHOO", (ValueType)"Yahoo! inc ");
printf("Key : %s , Value : %s\n", "MSFT", CHT_Get(HT, (KeyType)"MSFT"));
printf("Key : %s , Value : %s\n", "APAC", CHT_Get(HT, (KeyType)"APAC"));
printf("Key : %s , Value : %s\n", "ZYMZZ", CHT_Get(HT, (KeyType)"ZYMZZ"));
printf("Key : %s , Value : %s\n", "YHOO", CHT_Get(HT, (KeyType)"YHOO"));
CHT_DestroyHashTable(HT);
return 0;
}
'자료구조' 카테고리의 다른 글
| [ 자료구조 ] 해시 테이블 - 03 . 개방 주소법 (0) | 2023.04.06 |
|---|---|
| [ 자료구조 ] 해시 테이블 - 01 . 해시와 해시 테이블 (0) | 2023.04.03 |
| [자료구조] 우선순위 큐와 힙 - 03 . 우선순위 큐 구현 (0) | 2023.04.03 |
| [자료구조] 우선순위 큐와 힙 - 02 . 힙 구현 (0) | 2023.03.31 |
| [자료구조] 우선순위 큐와 힙 - 01 . 우선순위 큐와 힙 (0) | 2023.03.30 |



